Generating Fake Data- Density Estimation and Generative Adversarial Networks
1. Introduction

1. Introduction
In essence, Neural Networks are function approximators. Their popularity in the field comes from the fact that they are really good universal function approximators- promising to solve complex tasks like autonomous cars and language. However, regardless of the use case, at its highest level the system compromises of some sort of learned mapping from some input space X → g(X), where g is a neural network. Ten years ago coming up with the mapping function g was called feature engineering and was laboriously engineered by countless PhDs trying to mathematically model the underlying discriminative attributes of some data.
The networks that have come to spotlight in recent years belong to the wider class of Discriminative Networks. These networks map a rich high dimensional sensory inputs to a fixed set of class labels, but in real world not all problems can be solved in such a discriminative fashion. Often times we need to be able to probabilistically model the complex underlying problem that is not often observable.
In many cases, doing so successfully can often provide a more feasible approach from a computational standpoint as well. Doing so mathematically using machine learning leads to the field of Density Estimation. I will first explain density estimation using classical machine learning techniques and then move to the use of Generative Adversarial Networks (GANs) and their applications in the industry.
2. Density Estimation
Density Estimation is the process of constructing a model (an estimate) based on some observations. These observations come from an unobservable underlying probability distribution. You can think of the underlying and unobservable probability distribution as the density which dictates how something is distributed. The observations are thought of as random samples from that underlying distribution and the idea is that if we get enough independent and identically distributed random samples from the underlying distribution then we will be able to estimate or model the actual density.
Explaining this in layman’s terms, think of a scenario when a child asks you to explain what a car looks like. Say you draw for him your favorite car- a beautiful ferrari. By drawing this and showing the child that this is a car, what are you essentially doing? Without much thought, you are essentially randomly sampling from the set of all possible cars. Say now, just for further
clarification to the child, you draw a picture of the Ford Model T. Now the child has observed another example of a car from the set of all possible cars. Note how this process resembles one of a generative model- you are given some example data (random observations) of what a car looks like and are told to construct a model of a car in your head. This is different than a discriminative process where you are shown what a car looks like and what a car doesn’t look like- a motorcycle, and then are told to learn the differences. This also builds your understanding of what a car looks like, but the questions these two ways methods are asking are different hence the process is different.’
2.1 Methods of Density Estimation
Before the advent of generative neural networks, which we will explore later, there were two types of methods which are still widely used today: Parametric and non-Paramteric density estimations. These two different models ask different questions and assume different things given some randomly sampled data D. Parametric distributions are pretty straight forward: It assumes that we know the shape of the data but not the parameters. Mathematically speaking, the distribution is modeled using a set of parameters Θ and essentially tries to find p(D|Θ).
In the most simplest case of Parametric Density Estimation, we try to maximize p(D|Θ) which means that we choose a parameter Θ which makes the observed data more probable i.e. maximizing the probability of obtaining the data that was observed. A simpler way of understanding this is if I gave you a fake coin which gives heads with some probability p and tell you to figure out the underlying model and find the probability of head. You will probably start to get some observations or some trials. Say you flip it a 1000 times and get 750 heads. You can deduce that the probability of heads, p ̃, is 0.75 and is a reasonably close approximation to p because we performed a lot of trials. This is essentially the simplest form Parametric Density Estimation- you chose a parameter (probability of heads in this case) that maximized the chances of you observing the same data again i.e. observing 750 heads after 1000 trials. This method of estimation is also known as Maximum Likelihood Estimation and is based on finding the mean and the variance estimates that maximizes the likelihood of the observed data. There are other forms of Parametric Estimations as well.
However, there was one key assumption that we made in the previous method. In the coin flipping example we assumed that the underlying probability distribution is Bernoulli in nature- it has only two outcomes success or failure. For more complex distributions we could assume that
the distribution is a multivariate Gaussian- in fact Linear Regression assumes that its errors are normally distributed. Regardless of our assumption, it is still an assumption. In non-parametric modeling neither the probability distribution and nor the discriminant function is known- all we have is unlabeled data so the question we ask here is how we can estimate the probability distribution from just the labeled data. One of the most simpler and popular ones- K-Nearest Neighbors is actually a form of Non-Parametric technique among others like Parzen window Density estimates which can fit more complex distributions and don’t suffer from the same problems as K-NN.
3. Where are the Neural Networks?
The basic story to generate data from neural networks is that we sample x from some efficiently sample-able distribution, and output g(x), where g is a neural network. Using pushforward notation, we can define a random sample z ∼ μ where μ is some efficiently samples distribution-Uniform or even Gaussian. We output g(z), where g is a neural network and call the new distribution g#μ. Therefore, intuitively g(x) takes a random sample x from some input space X and maps it to some output space g#μ. Neural networks in this case acts like a very complex mapping function. To understand this better, let’s look at some simpler examples of the function g. The figures below show how we tailor g to map random uniform samples (left) to some target
distribution (right).

This is essentially what GANs are doing. To run a neural network to output a probability distribution, we choose some sort of randomness like uniform or gaussian or any efficiently sample-able/ in “constant time” distribution- sample from that, and then output the new distribution g(z) where the mapping g is learned through a neural network. I think it is safe to say how weird this method is.
3.1 GAN Formulation


where F is the set of all adversaries/ discriminators/ critics. Here, we interpret F as a probability, Pr[x is fake].


To train the algorithm, we alternate between two steps. We hold g fixed and optimize over all f. We optimize the following first:

and then in step 2 we hold f fixed and then optimize g.
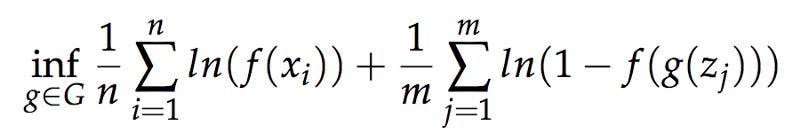
where zj is the jth output of the network g from a random sample z from the uniform distribution µ.
This constant push and pull of the objective function is also known as adversarial training where one network is trying to fool the other one, while the other one is trying to not get fooled. The result is that the generator learns to create samples that are very real and by doing so slowly learns the underlying and unobservable probability distribution that we discussed in the beginning of this article.
4. Applications
Today, in research we are only beginning to scratch the surface of the applications of adversarial training. GANs rose into popularity when they were able to generate real-life looking face samples. Below are some examples of sample output images where a GAN was trained to generate faces.
